KOPI
Quick login


Login
Documents

We encounter contents that are plagiarised or copied on a word-by-word basis more and more frequently, both in higher education and in scientific life. To find such contents several solutions have already been set up, of which KOPI Plagiarism Checker, developed and operated by SZTAKI DSD is the best-known in the Hungarian language. However, the spread of the Internet and the fact that more people speak foreign languages generated a new form of plagiarism, tranlational plagiarism. Today most students can speak at least one foreign language - mainly English - on a level which enables them to find materials relevant to a given topic on foreign websites, and to translate them as well. This skill is also an expectation towards students, as today a thesis that does not contain reference to foreign language literature is not accepted by most universities, and/or faculties. Foreign language knowledge also gives students the opportunity to translate such materials and to use them, without giving their source, as an own idea, own piece of work instead of elaborating such materials. Given such situation, even when the professors, teachers try to check the suspicious part and enter a Hungarian sentence, web-based plagiarism checkers cannot locate a relevant English-language content. For this reason we strongly believe that it is time to move on from monolingual plagiarism checkers, so in 2010 we started a one-year research on how it is possible to clear a Hungarian text as an own piece of work by the student, or as a mere translation.
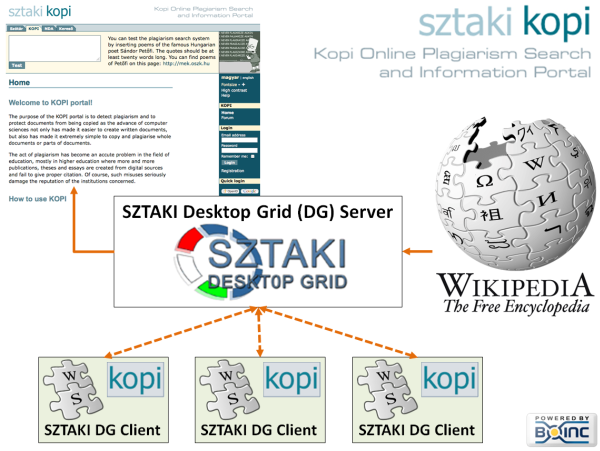
As a result of our research we have developed an algorithm that helps us find the translation of a given sentence or text quickly, even in a large foreign language content. To facilitate this search function we have to process the foreign language sources first. As it needs a great deal of computation capacity and time, we have decided to place the text processing, especially that of Wikipedia, on a GRID basis.
The English Wikipedia consists of nearly 4 million articles, and is about 30GB, without the pictures and the accessory data. To process such a great amount of data large computation capacity is a must. To ensure that the database of the plagiarism-checker is up-to-date, we have to process the datasets from Wikipedia on a monthly basis. We are able to do this with the help of the donors linked to the SZTAKI Desktop Grid: we split the dataset into smaller parts, transfer them into textual format, split them into sentences, and then we take the stem of all words.
KOPI is a free service to be used, as we aim to improve the quality of the Hungarian higher education and the value of degrees by eliminating potential misuse of foreign language information.
If you would like to help us please visit the page of SZDG.