KOPI
Gyors belépés


Belépés
Dokumentumok
A felsőoktatásban és a tudományos életben is egyre gyakrabban találkozunk szó szerint lemásolt, plagizált tartalommal. Ennek felkutatására számos megoldás született már, ezek közül magyar nyelven a SZTAKI Elosztott Rendszerek Osztálya által üzemeltetett KOPI Plágiumkereső a legismertebb. Az internet és az idegennyelv-tudás elterjedése azonban a plágiumok egy új formájának - fordítási plágiumok - térhódítását is magával hozta. A legtöbb diák ma már elég jól beszél legalább egy idegen nyelven - tipikusan angolul - ahhoz, hogy külföldi oldalakon és tartalmakban is megtalálja az adott témába vágó irodalmakat és képes legyen azt lefordítani. Ez elvárás is felé, hiszen ma már egy olyan diploma, amelyik nem tartalmaz utalást a külföldi irodalmakra, a legtöbb egyetemen, illetve szakon, nem fogadható el. Ez a nyelvtudás ugyanakkor megteremti a lehetőséget arra is, hogy a diák az idegen nyelvű anyagok feldolgozása helyett azt egyszerűen csak lefordítsa, és az adott forrás megjelölése nélkül, saját gondolataként, saját munkájaként adja be. Ilyen esetekben az oktatók hiába keresnek rá a gyanús részekre, a webes keresők egy magyar mondat beírásakor nem képesek az annak megfelelő angol tartalmakat előhozni. Ezért éreztük úgy, hogy ideje továbblépni az egynyelvű keresőktől és 2010-ben egy egyéves kutatásba kezdtünk, hogy miként lehetne egy magyar szövegről megállapítani, hogy az a diák saját munkája-e, vagy csak egy fordítás.
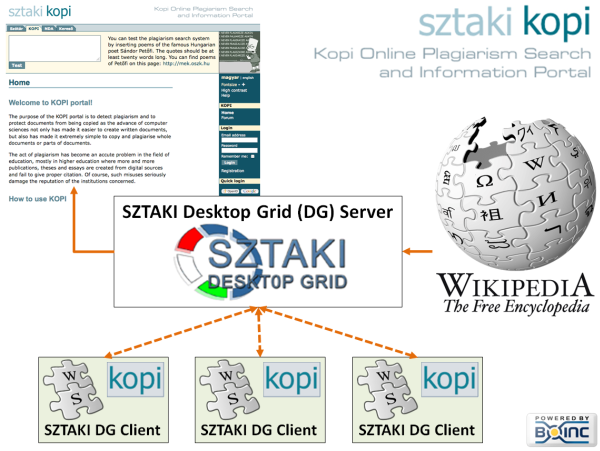
Ennek a kutatásnak az eredményeképp kifejlesztettünk egy algoritmust, amelynek segítségével nagy mennyiségű idegen nyelvű szövegben gyorsan meg lehet találni egy adott mondat, vagy szövegrész fordítását. Ahhoz, hogy ez működjön, az idegen nyelvű forrást részletesen fel kell dolgoznunk, mielőtt kereshetnénk benne. Ez sok időt és számítási kapacitást igényel, ezért döntöttünk úgy, hogy GRID alapokra helyezzük a szövegfeldolgozást, ezen belül is kiemelten a Wikipédia feldolgozását.
Az angol nyelvű Wikipédia közel 4 millió cikket tartalmaz, és körülbelül 30GB-os, képek és járulékos adatok nélkül. Ekkora mennyiségű adat feldolgozásához nagyon nagy számítási teljesítményre van szükség. Ahhoz, hogy a plágium kereső adatbázisa naprakész tudjon maradni, a körülbelül havonta megjelenő Wikipédiból származó adathalmazt fel kell dolgozni. Ezt végezzük el a SZTAKI Desktop Gridhez csatlakozó donorok segítségével: feldaraboljuk kisebb részekre, átalakítjuk szöveges formába, mondatokra bontjuk, majd az összes szónak vesszük a szótövét.
A KOPI egy ingyenesen használható szolgáltatás, célunk vele, hogy a magyar felsőoktatás minőségét és a diplomák értékét növeljük azáltal, hogy minél több értékes diploma szülessen.
Ha segíteni szeretne ebben a munkában, kérjük látogasson el az SZDG oldalára.